Overview
Our research primarily focuses on fundamental theories and key technologies in artificial intelligence and computer vision, with an emphasis on intelligent perception and embodied intelligence in open and complex environments. Our goal is to move beyond traditional static visual understanding paradigms and advance intelligent systems from passive perception toward autonomous agents capable of cognition, decision-making, and action. In recent years, our research has centered on open-world visual understanding and 3D environmental perception, aiming to systematically investigate perception, reasoning, and decision-making mechanisms of intelligent agents operating in real-world dynamic environments. Our research topics include autonomous driving perception and scene understanding, embodied navigation and interactive learning, 3D visual perception and scene modeling, multimodal vision–language understanding, and unified Vision–Language–Action modeling frameworks. These efforts seek to enable intelligent systems to achieve continual generalization and adaptive capability under unseen environments and distribution shifts. In parallel, we study the reliability and interpretability of deep learning models, with particular attention to generalization mechanisms in open environments, out-of-distribution robustness, and trustworthy learning principles. By integrating representation learning, causal reasoning, and structured modeling, we aim to understand the underlying behavioral mechanisms of intelligent models from a theoretical perspective and provide methodological foundations for building generalizable, interpretable, and reliable intelligent perception systems.
Highlights
1. Embodied Intelligence: From Perception to Action
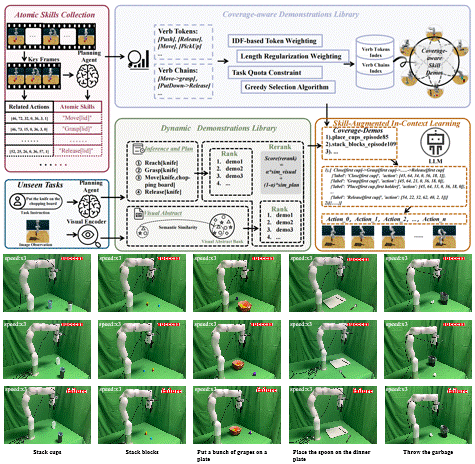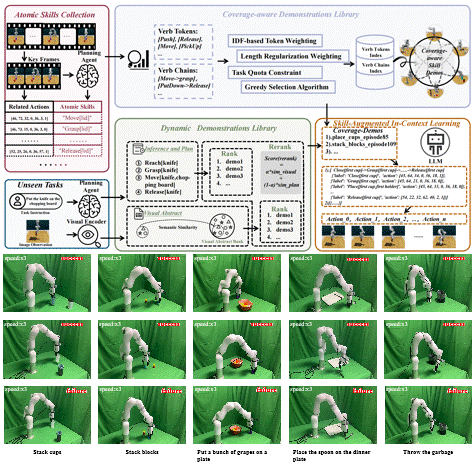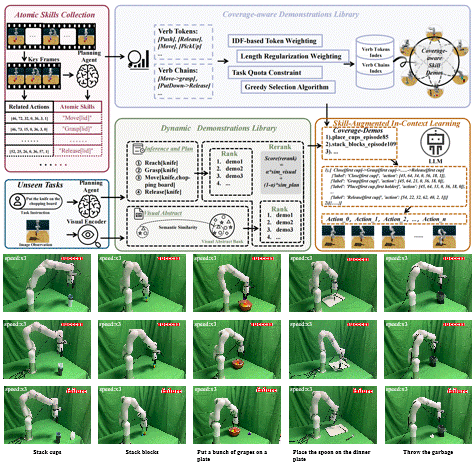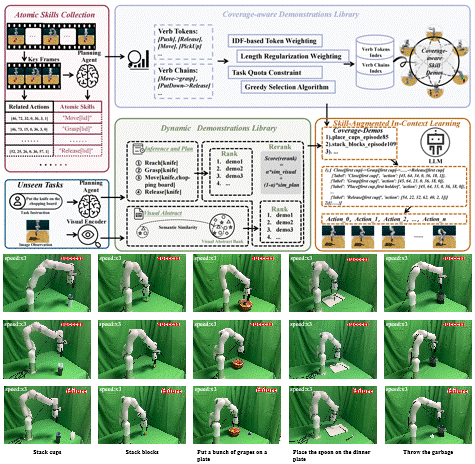
1 Decompose and Recompose: Reasoning New Skills from Existing Abilities for Cross-Task Robotic Manipulation
Xitie Zhang, Aming Wu, Yahong Han
ICML 2026, (Project Page)
Cross-task generalization is a core challenge in open-world robotic manipulation, and the key lies in extracting transferable manipulation knowledge from seen tasks. In this work, we propose Decompose and Recompose, a skill reasoning framework using atomic skill-action pairs as intermediate representations. Our approach decomposes seen demonstrations into interpretable skill-action alignments, enabling the model to recompose these skills for unseen tasks through compositional reasoning. Specifically, we construct a task-adaptive dynamic demonstration library via visual-semantic retrieval combined with skill sequences from a planning agent, complemented by a coverage-aware static library to fill missing skill patterns. Together, these yield skill-comprehensive demonstrations that explicitly elicit compositional reasoning for skill composition and execution.
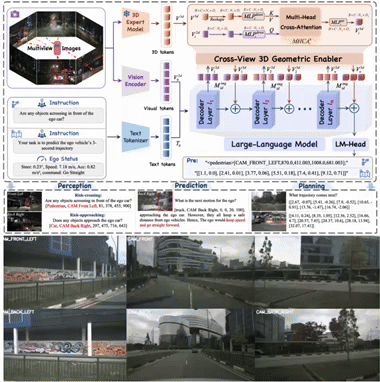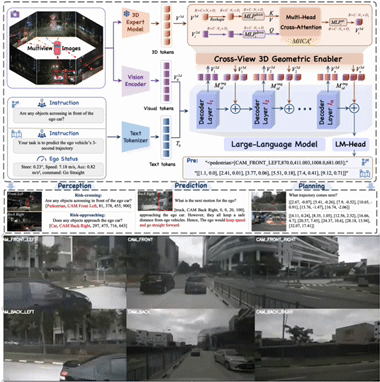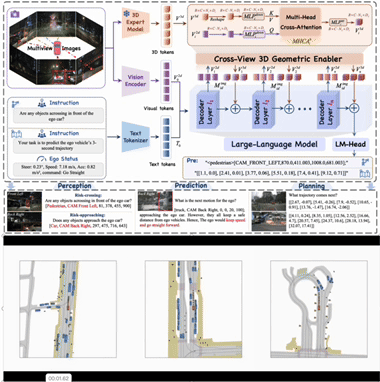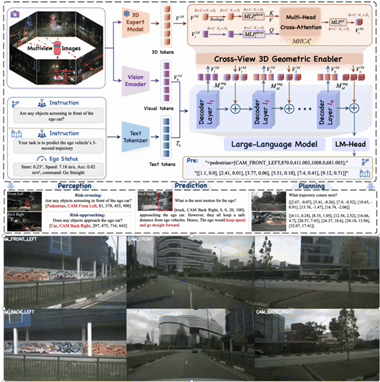
2 VGGDrive: Empowering Vision-Language Models with Cross-View Geometric Grounding for Autonomous Driving
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, Long Chen
CVPR 2026, (Preprint), (Project Page)
Cross-view 3D geometric modeling is crucial for autonomous driving, yet existing Vision–Language Models (VLMs) lack explicit geometric reasoning capability, resulting in limited performance in complex driving scenarios. Current auxiliary training strategies based on Q&A supervision attempt to alleviate this issue but fail to fundamentally address the absence of geometric grounding.
To overcome this limitation, we propose VGGDrive, an architecture that equips VLMs with cross-view geometric grounding by leveraging mature 3D foundation models. A plug-and-play Cross-View 3D Geometric Enabler (CVGE) is introduced to bridge 3D spatial representations and 2D visual features without altering the original VLM structure. Extensive experiments on five autonomous driving benchmarks demonstrate consistent performance improvements, highlighting the effectiveness of integrating 3D foundation models for geometry-aware autonomous driving.
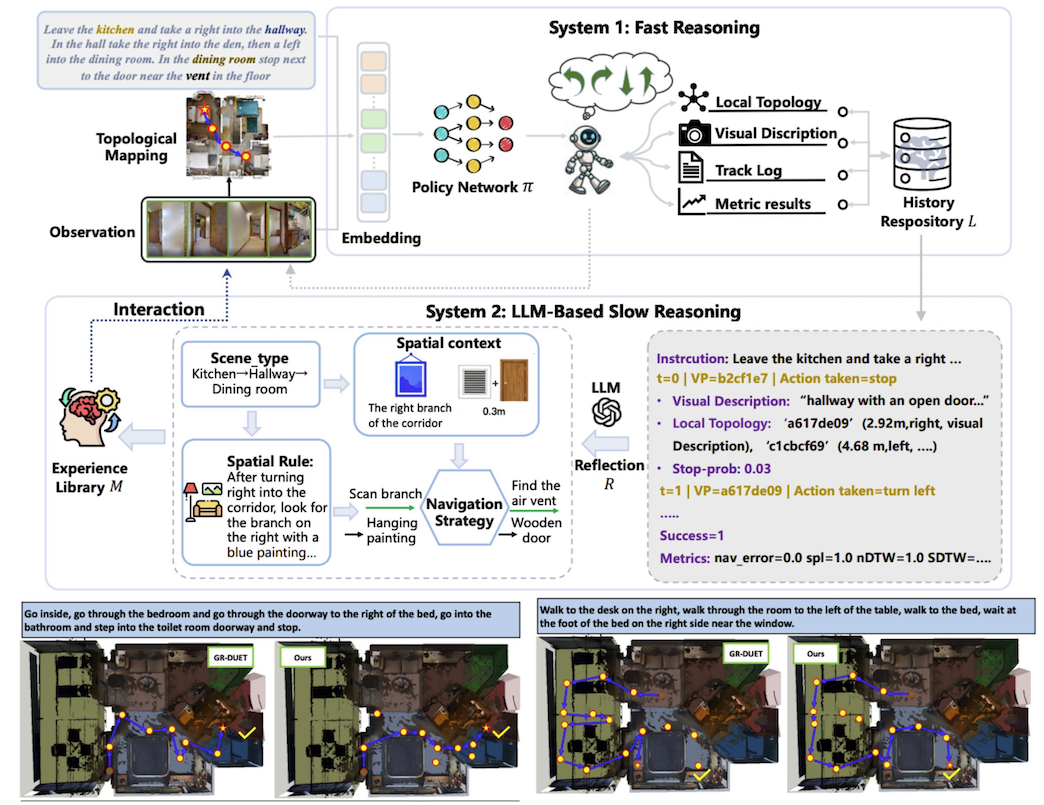
3 Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning
Yang Li, Aming WU, Zihao Zhang, Yahong Han
CVPR 2026,(Preprint), (Project Page)
We focus on the GSA-VLN task, aiming to learn generalized navigation ability by introducing diverse environments and inconsistent intructions. Recent research indicates that by means of fast and slow cognition systems, human beings could generate stable policies, which strengthen their adaptation for open world. Inspired by this idea, we propose the slow4fast-VLN, establishing a dynamic interactive fast-slow reasoning framework. The fast-reasoning module, an end-to-end strategy network, outputs actions via real-time input. It accumulates execution records in a history repository to build memory. The slow-reasoning module analyze the memories generated by the fast-reasoning module. Through deep reflection, it extracts experiences that enhance the generalization ability of decision-making. These experiences are structurally stored and used to continuously optimize the fast-reasoning module. Unlike traditional methods that treat fast-slow reasoning as independent mechanisms, our framework enables fast-slow interaction. By leveraging the experiences from slow reasoning, it continually improves the generalization ability of fast decisions.

4 Autonomous Mobile Robotic Arm for Intelligent Perception and Grasping
This video showcases the latest progress in our laboratory’s research on Embodied Intelligence. In the experiment, a mobile robotic arm autonomously perceives its environment, intelligently plans its path, and skillfully avoids obstacles to achieve highly efficient object grasping. This technology significantly enhances the robot’s adaptability to dynamic environments by seamlessly integrating perception, decision-making, and control. It holds significant potential for applications in smart manufacturing, automated logistics, and service robotics. Moving forward, we will explore deep learning and reinforcement learning methods in embodied intelligence to equip robots with greater autonomy and generalization capabilities in complex environments.
2. Visual Understanding in Practical Scenes: Open-World Perception
1 Prototype-Anchored Generalized Manifold Regression for Unknown-Domain Object Detection
Zihao Zhang, Aming Wu, Yang Li, Yahong Han
IEEE TPAMI, DOI: 10.1109/TPAMI.2026.3714053, (Project Page)
Single-Domain Generalized Object Detection aims to generalize a detector trained on a single source domain to multiple unseen target domains. The key challenge lies in handling complex and dynamic visual variations without accessing target-domain data during training. Existing methods usually rely on simulation-based strategies, such as discrete data augmentation or static textual prompts, to enlarge the source distribution. However, finite simulations are difficult to cover the infinite variations of real-world scenarios and may lead to overfitting to synthetic styles. Inspired by the manifold hypothesis, we argue that semantic features under diverse visual conditions should lie on a compact and stable low-dimensional manifold. To this end, we propose Manifold Regression with Visual-Text Dual Chain-of-Thought (MR-DCoT), which reformulates unknown-domain generalization as a prototype-anchored manifold regression problem. Specifically, MR-DCoT generates structured off-manifold hard examples through visual-text dual reasoning and learns class-specific prototype anchoring to project deviant features back to the stable source semantic manifold. This closed-loop design between outlier generation and semantic correction effectively improves detection robustness under complex unseen domain shifts.
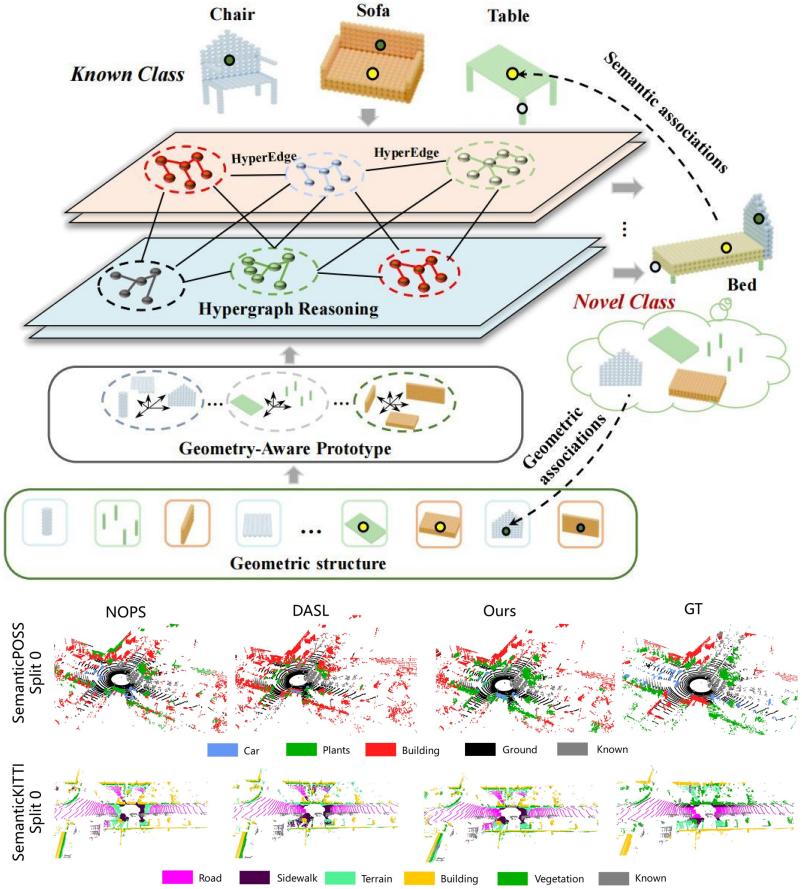
2 Geometric-Aware Hypergraph Reasoning for Novel Class Discovery in Point Cloud Segmentation
Zihao Zhang, Yang Li, Aming Wu, Yahong Han, Jialie Shen
CVPR 2026(Preprint), (Project Page)
Novel Class Discovery in Point Cloud Segmentation has recently attracted increasing attention, aiming to leverage knowledge from known classes to automatically discover and segment unlabeled novel categories in point clouds. The key challenge lies in effectively transferring both geometric and semantic knowledge from multiple known classes to enable reliable understanding of unseen categories. However, existing methods mainly rely on pairwise associations for class assignment and reasoning, overlooking higher-order relationships among classes. Such binary modeling limits the ability to capture complex inter-class dependencies, often resulting in ambiguous semantic predictions for novel classes. To address this issue, we introduce a hypergraph structure to explicitly model high-order associations, enabling collaborative reasoning from multiple known classes toward novel categories. In addition, prior approaches tend to emphasize semantic features while underutilizing geometric information, whereas our method jointly exploits geometric and semantic cues to achieve more accurate and robust novel class segmentation.
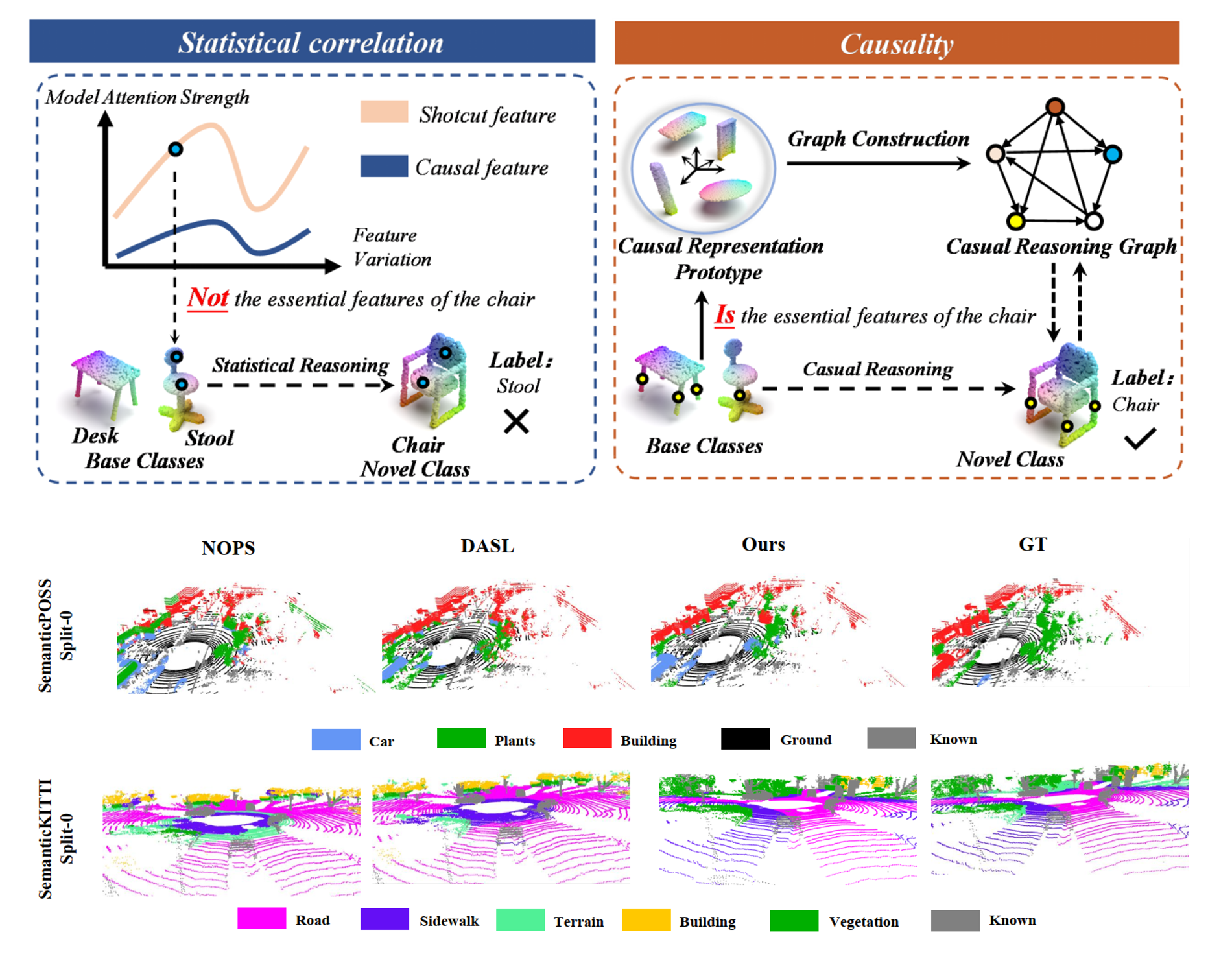
3 Novel Class Discovery for Point Cloud Segmentation via Joint Learning of Causal Representation and Reasoning
Yang Li, Aming Wu, Zihao Zhang, Yahong Han
NeurIPS 2025,(Preprint), (Project Page)
We focus on 3D-NCD, which aims to train a model for segmenting unlabeled (novel) 3D classes using only supervision from labeled (base) 3D classes. To address this, we propose imposing causal relationships as strong constraints to uncover class-aligned essential point cloud representations. We introduce a Structural Causal Model (SCM) to redefine the 3D-NCD problem and present a new method: Joint Learning of Causal Representation and Reasoning. Specifically, the method uses SCM to analyze hidden confounders in base class representations and causal links between base and novel classes; designs a causal representation prototype to eliminate confounders and capture base classes’ causal representations; and employs a graph to model causal relationships between base class causal prototypes and novel class prototypes, enabling base-to-novel causal reasoning.
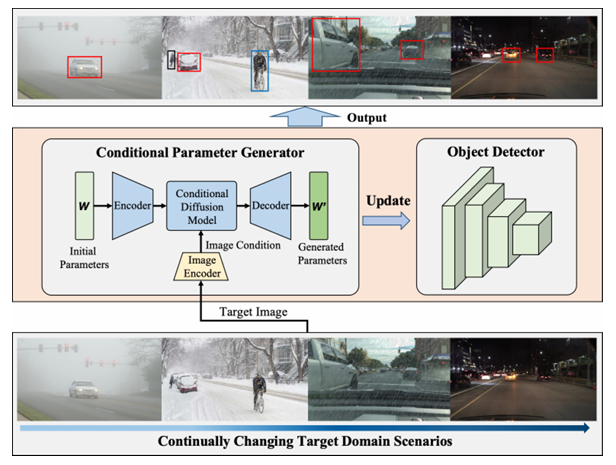
4 Continual Adaptation: Environment-Conditional Parameter Generation for Object Detection in Dynamic Scenarios
Deng Li, Aming Wu, Yang Li, Yaowei Wang, Yahong Han
ICCV 2025,(Preprint)
Environments change over time and space, challenging object detectors trained on a closed-set assumption, where training and test data share the same distribution. To address this, continual test-time adaptation has emerged, aiming to fine-tune specific parameters (e.g., BatchNorm) to improve generalization. However, fine-tuning a few parameters may degrade the representation of others, leading to performance issues. We propose a new approach that converts fine-tuning into specific-parameter generation. Our method uses a dual-path LoRA-based domain-aware adapter that separates features into domain-invariant and domain-specific components for efficient adaptation. We also introduce a conditional diffusion-based parameter generation mechanism to synthesize adapter parameters based on the current environment, avoiding local optima. Lastly, a class-centered optimal transport alignment is used to prevent catastrophic forgetting.
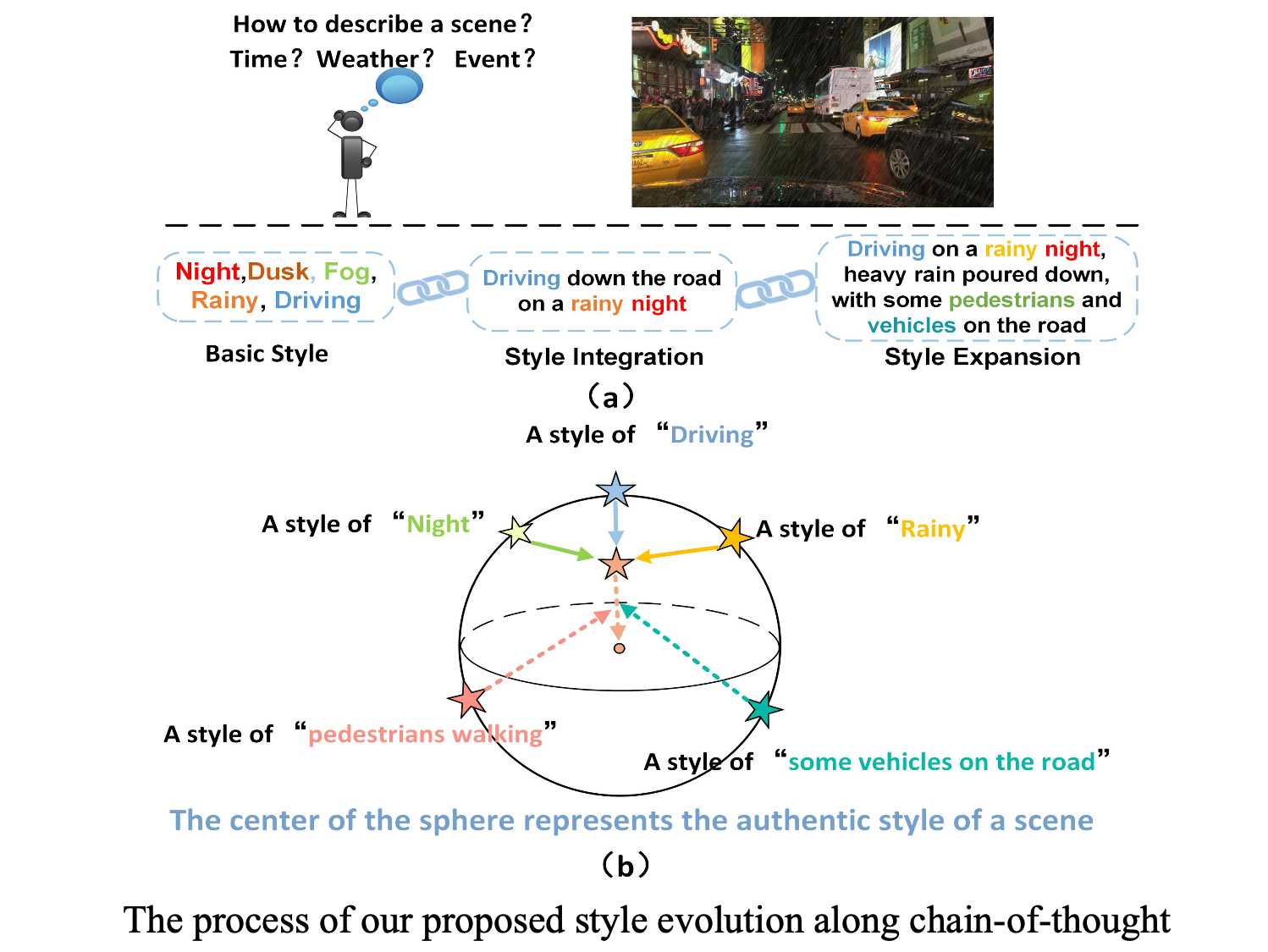
5 Style Evolving along Chain-of-Thought for Unknown-Domain Object Detection
Zihao Zhang, Aming Wu, Yahong Han
CVPR 2025, (Highlights), (Preprint), (Project Page)
In this work, we propose a new method, i.e., Style Evolving along Chain-of-Thought, which aims to progressively integrate and expand style information along the chain of thought, enabling the continual evolution of styles. Specifically, by progressively refining style descriptions and guiding the diverse evolution of styles, this method enhances the simulation of various style characteristics, enabling the model to learn and adapt to subtle differences more effectively. Additionally, it exposes the model to a broader range of style features with different data distributions, thereby enhancing its generalization capability in unseen domains. The significant performance gains over five adverse-weather scenarios and the Real to Art benchmark demonstrate the superiorities of our method.
3. Adversarial Vision and Robustness: Towards AI Security
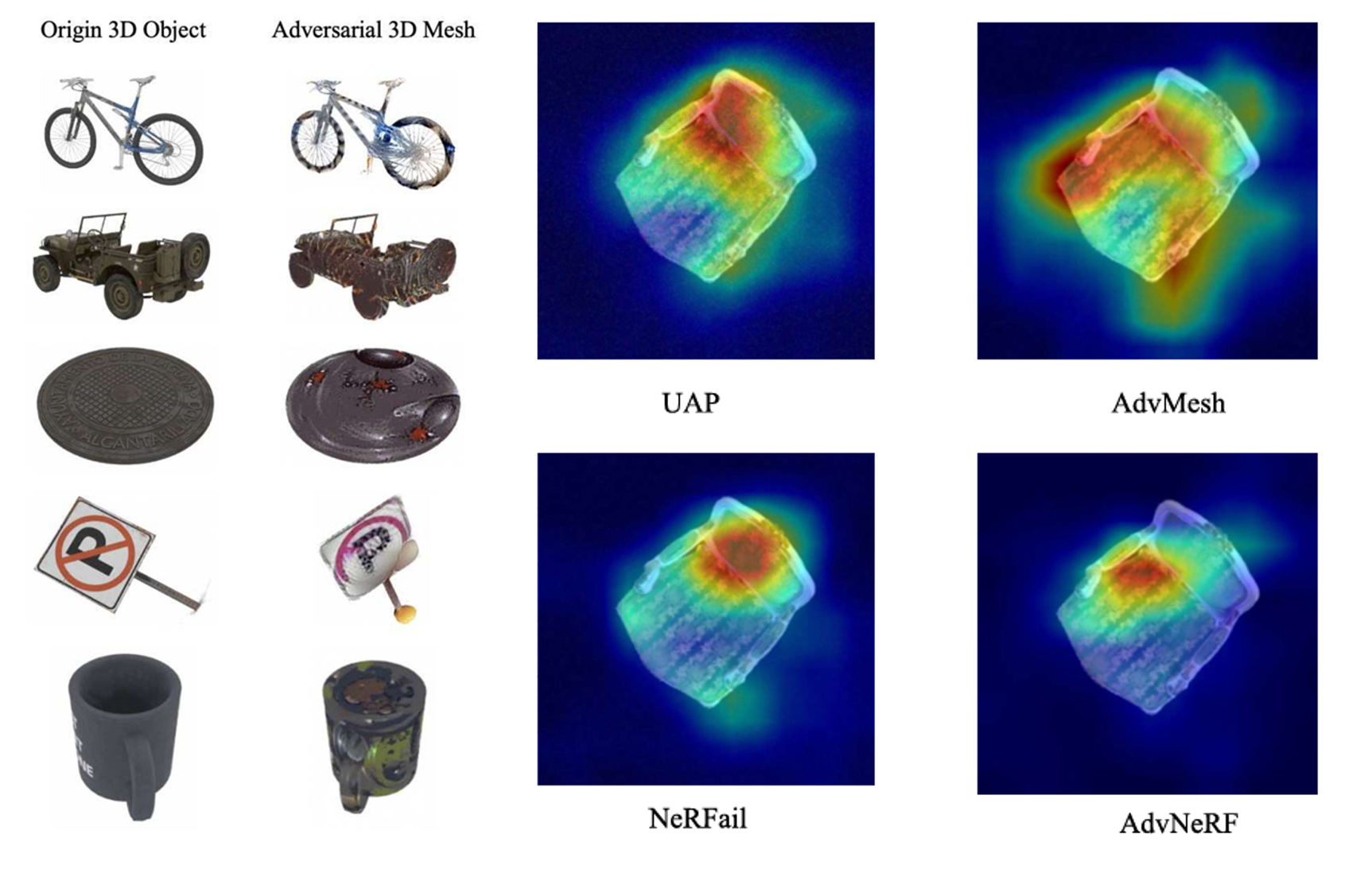
1 AdvNeRF: Generating 3D Adversarial Meshes With NeRF to Fool Driving Vehicles
Boyuan Zhang, Jiaxu Li, Yucheng Shi, Yahong Han, Qinghua Hu
IEEE TIFS, DOI: 10.1109/TIFS.2025.3609180 , (Project Page)
Adversarial attacks on deep neural networks (DNNs) pose risks, especially in safety-critical applications like autonomous driving. These vehicles rely on vision and LiDAR sensors for 3D perception, but adversarial vulnerabilities can mislead these systems, endangering safety. While existing research focuses on 2D-pixel image attacks, these lack real-world applicability in 3D. To address this, we propose AdvNeRF, a novel approach for generating 3D adversarial meshes targeting both vision and LiDAR models. AdvNeRF leverages Neural Radiance Fields (NeRF) to create high-quality adversarial objects, ensuring robustness across multiple viewpoints. Experimental results show that AdvNeRF significantly degrades 3D object detectors, highlighting its potential to compromise autonomous vehicle perception systems from various perspectives. This marks a key advancement in 3D adversarial attacks.
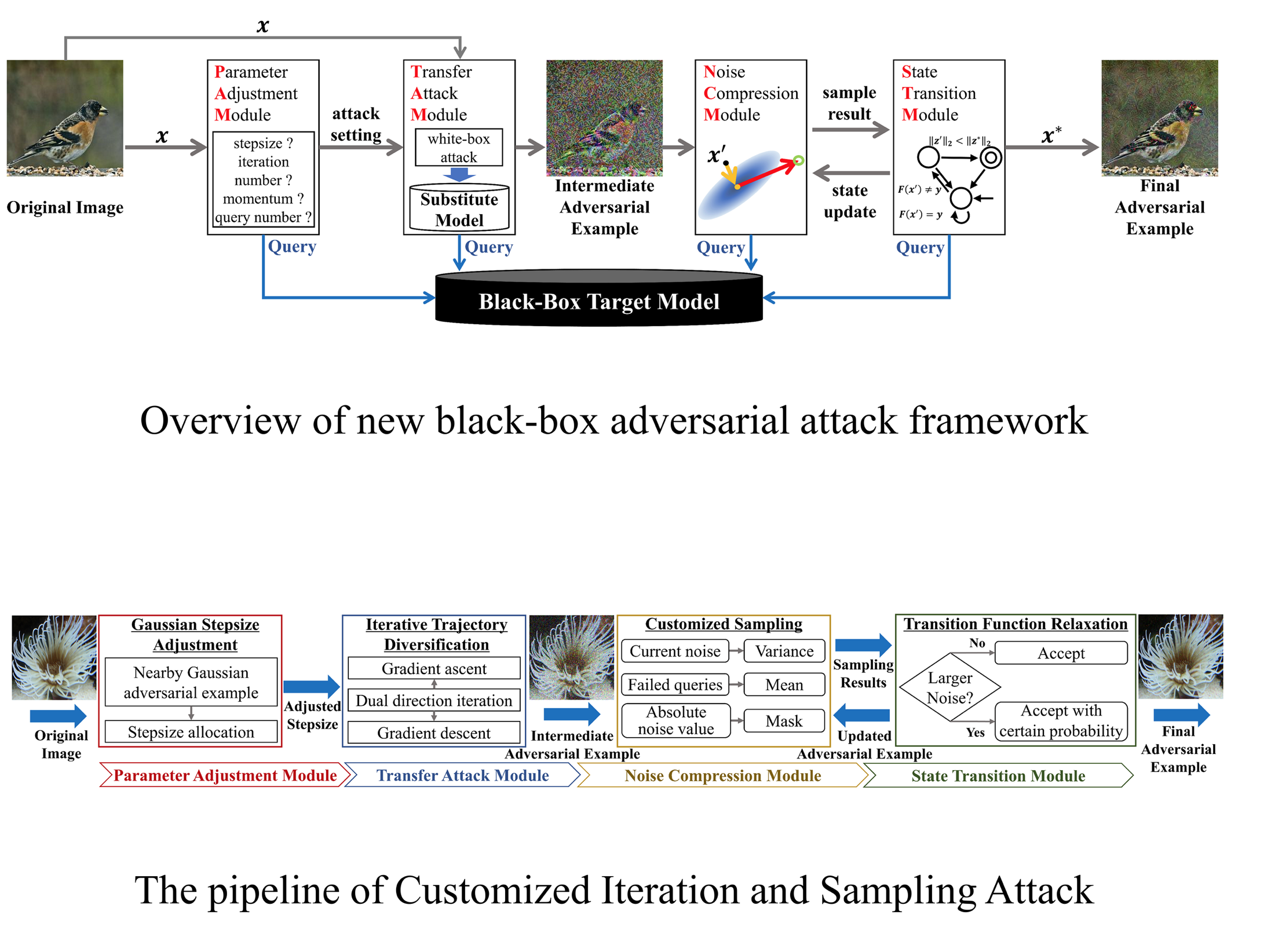
2 Query-efficient Black-box Adversarial Attack with Customized Iteration and Sampling
Yucheng Shi, Yahong Han, Qinghua Hu, Yi Yang, Qi Tian
IEEE TPAMI, DOI:10.1109/TPAMI.2022.3169802, (Project Page)
In this work, a new framework bridging transfer-based and decision-based attacks is proposed for query-efficient black-box adversarial attack. We reveal the relationship between current noise and variance of sampling, the monotonicity of noise compression in decision-based attack, as well as the influence of transition function on the convergence of decision-based attack. Guided by the new framework and theoretical analysis, we propose a black-box adversarial attack named Customized Iteration and Sampling Attack (CISA). CISA estimates the distance from nearby decision boundary to set the stepsize, and uses a dual-direction iterative trajectory to find the intermediate adversarial example. Based on the intermediate adversarial example, CISA conducts customized sampling according to the noise sensitivity of each pixel to further compress noise, and relaxes the state transition function to achieve higher query efficiency.
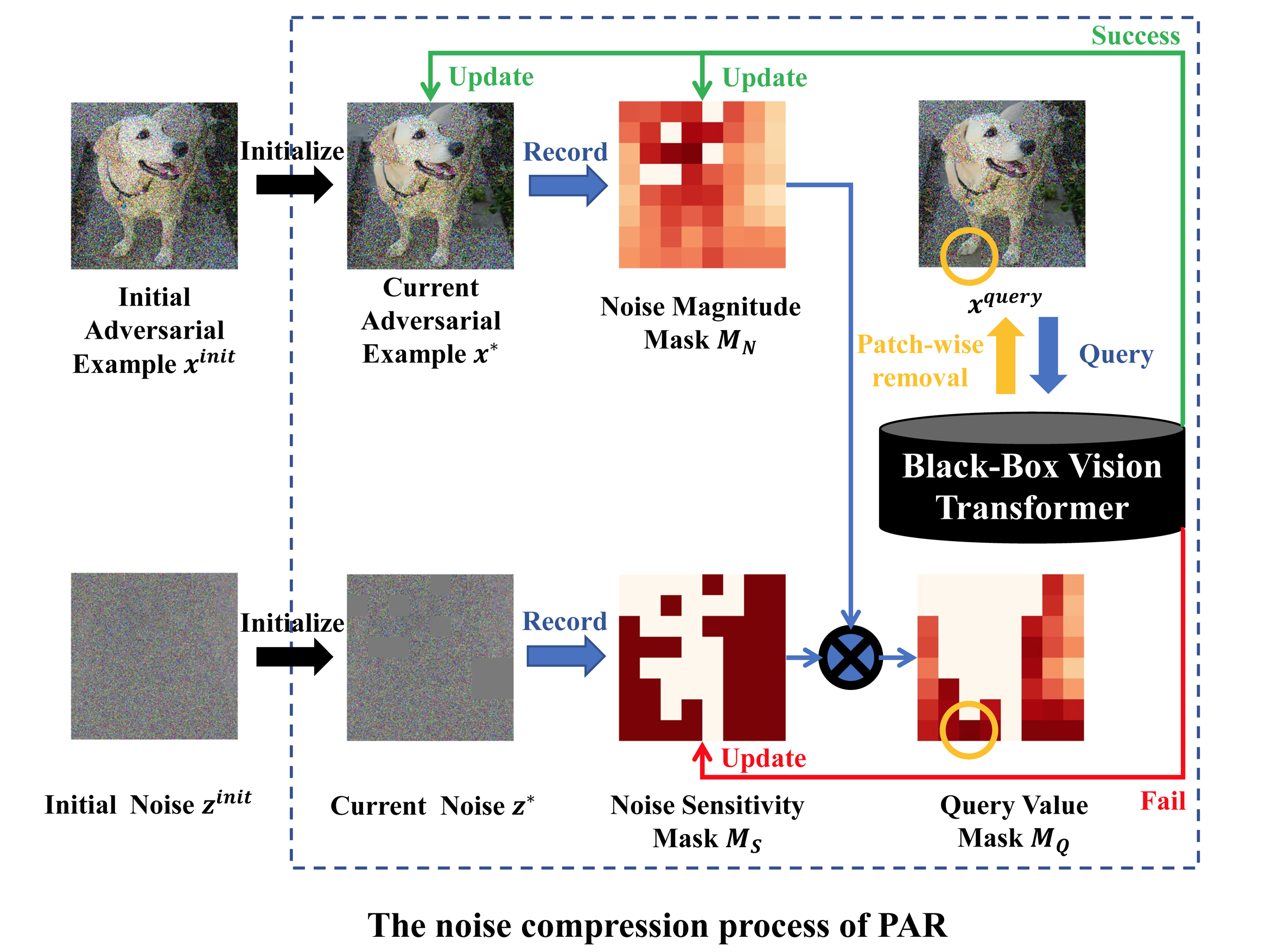
3 Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal
Yucheng Shi, Yahong Han, Yu-an Tan, Xiaohui Kuang
NeurIPS 2022, https://arxiv.org/abs/2112.03492, (Project Page)
In this paper, we theoretically analyze the limitations of existing decision-based attacks from the perspective of noise sensitivity difference between regions of the image, and propose a new decision-based black-box attack against ViTs, termed Patch-wise Adversarial Removal (PAR). PAR divides images into patches through a coarse-to-fine search process and compresses the noise on each patch separately. PAR records the noise magnitude and noise sensitivity of each patch and selects the patch with the highest query value for noise compression. In addition, PAR can be used as a noise initialization method for other decision-based attacks to improve the noise compression efficiency on both ViTs and CNNs without introducing additional calculations. Extensive experiments on three datasets demonstrate that PAR achieves a much lower noise magnitude with the same number of queries.
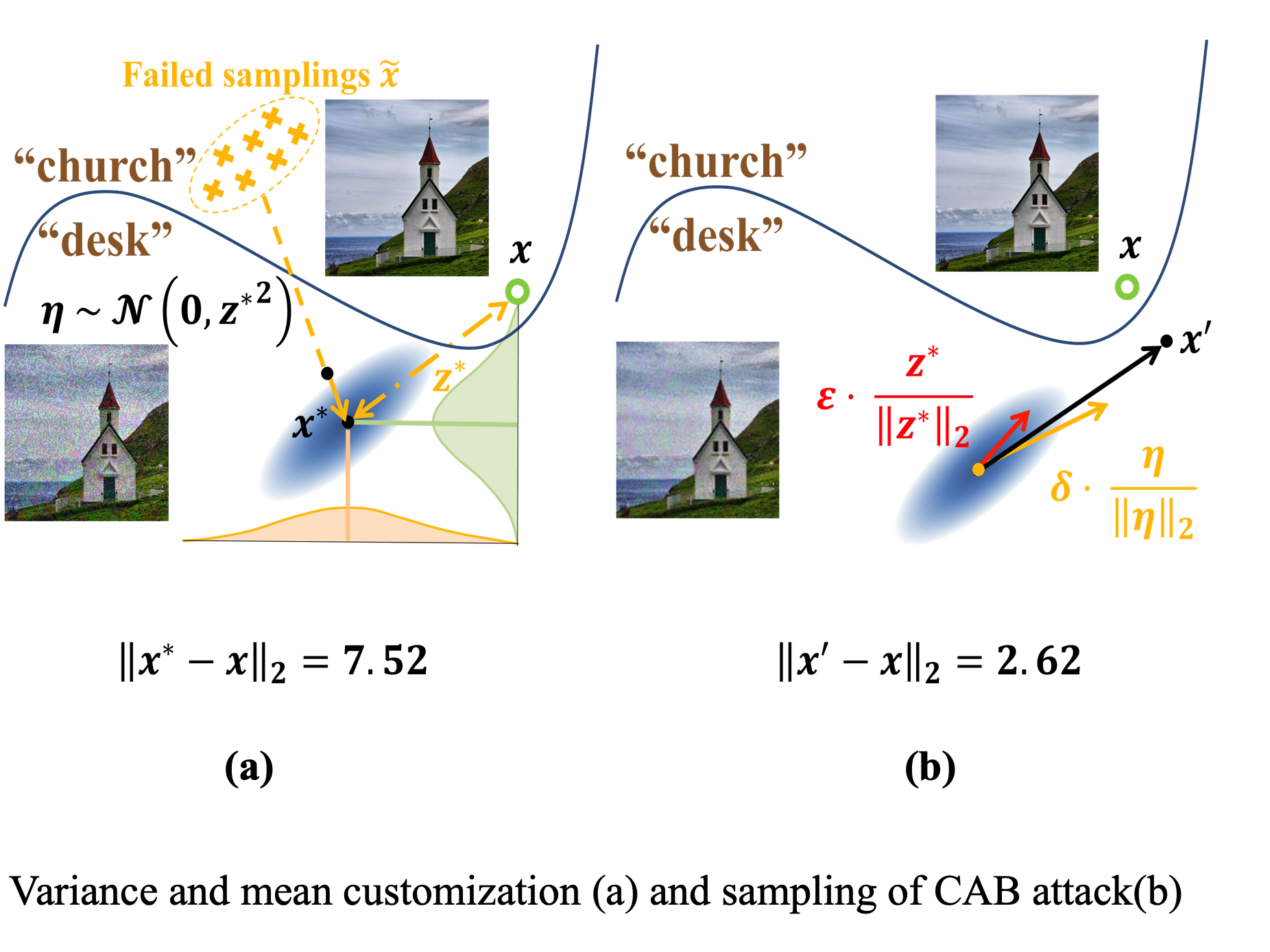
4 Polishing Decision-based Adversarial Noise with a Customized Sampling
Yucheng Shi, Yahong Han, Qi Tian
CVPR 2020, (Project Page)
In this paper, we demonstrate the advantage of using current noise and historical queries to customize the variance and mean of sampling in boundary attack to polish adversarial noise. We further reveal the relationship between the initial noise and the compressed noise in boundary attack. We propose Customized Adversarial Boundary (CAB) attack that uses the current noise to model the sensitivity of each pixel and polish adversarial noise of each image with a customized sampling setting. On the one hand, CAB uses current noise as a prior belief to customize the multivariate normal distribution. On the other hand, CAB keeps the new samplings away from historical failed queries to avoid similar mistakes. Experimental results measured on several image classification datasets emphasizes the validity of our method.
4. Behavior-Level Collaborative Learning: multi-behavior recommendation
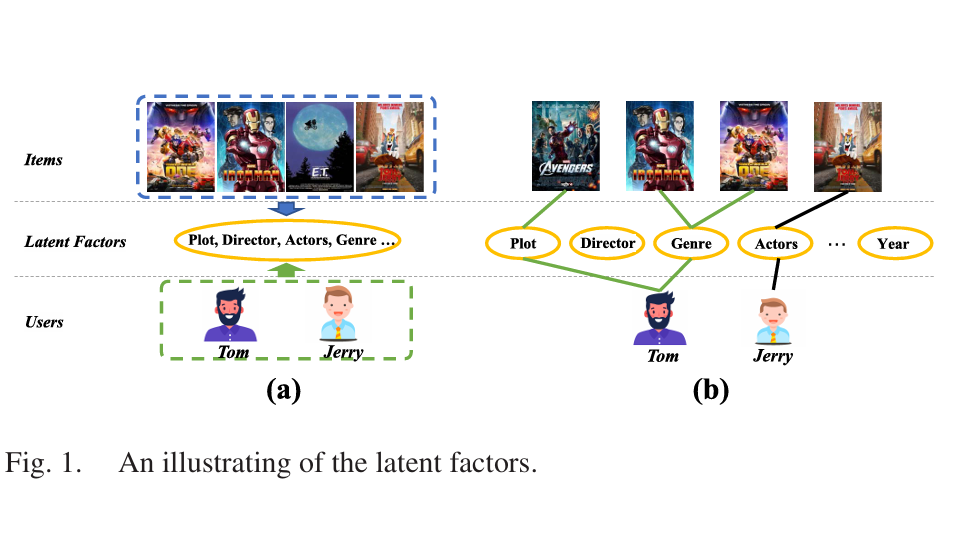
1 Latent Factor Modeling with Expert Network for Multi-Behavior Recommendation
Mingshi Yan, Zhiyong Cheng, Yahong Han, and Meng Wang
IEEE TKDE, DOI: 10.1109/TKDE.2025.3591503, (Project Page)
Traditional recommendation methods face data sparsity, while multi-behavior methods leverage diverse user data but often provide imprecise representations. To improve this, we propose MBLFE, a multi-behavior method using a gating expert network. Each expert specializes in a specific latent factor, and the gating network dynamically selects the optimal combination for each user. Self-supervised learning ensures expert independence and factor consistency. By incorporating multi-behavior data, our approach enriches embeddings and improves factor extraction. Experiments on three datasets show that MBLFE outperforms state-of-the-art methods, proving its effectiveness.
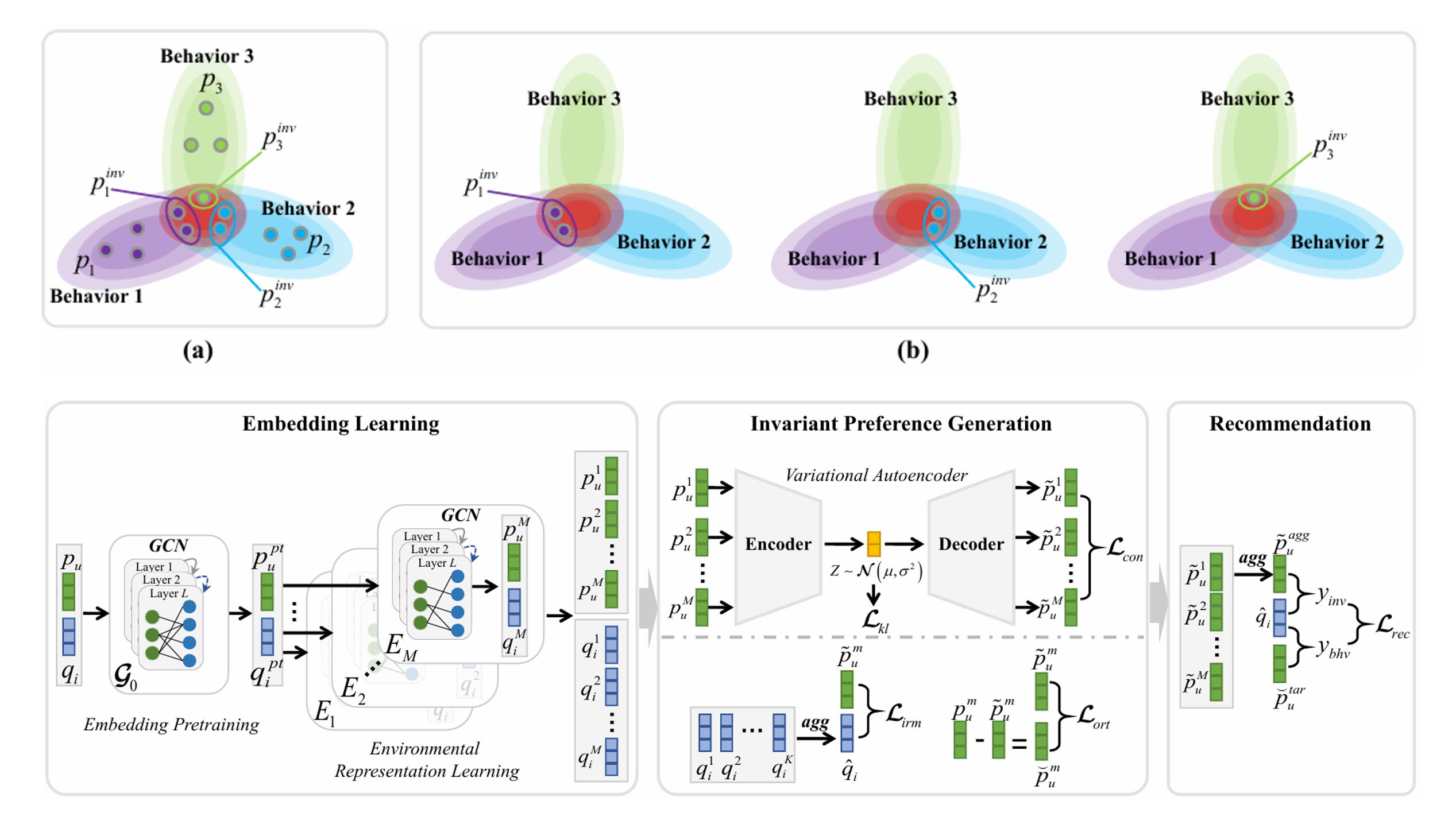
2 User Invariant Preference Learning for Multi-Behavior Recommendation
Mingshi Yan, Zhiyong Cheng,Fan Liu, Yingda Lyu, and Yahong Han
ACM Transactions on Information Systems (TOIS), DOI: https://doi.org/10.1145/3728465, (Project Page)
In multi-behavior recommendation, analyzing diverse behaviors (e.g., click, purchase, rating) helps understand users’ interests. However, existing methods often ignore the balance between commonalities and individualities in user preferences, where auxiliary behaviors may introduce noise. To address this, we propose UIPL (User Invariant Preference Learning), which captures users’ intrinsic interests (invariant preferences) by leveraging invariant risk minimization. We use a variational autoencoder (VAE) with an invariant risk minimization constraint, combining multi-behavior data to enhance robustness. Experiments on four datasets show UIPL outperforms state-of-the-art methods.
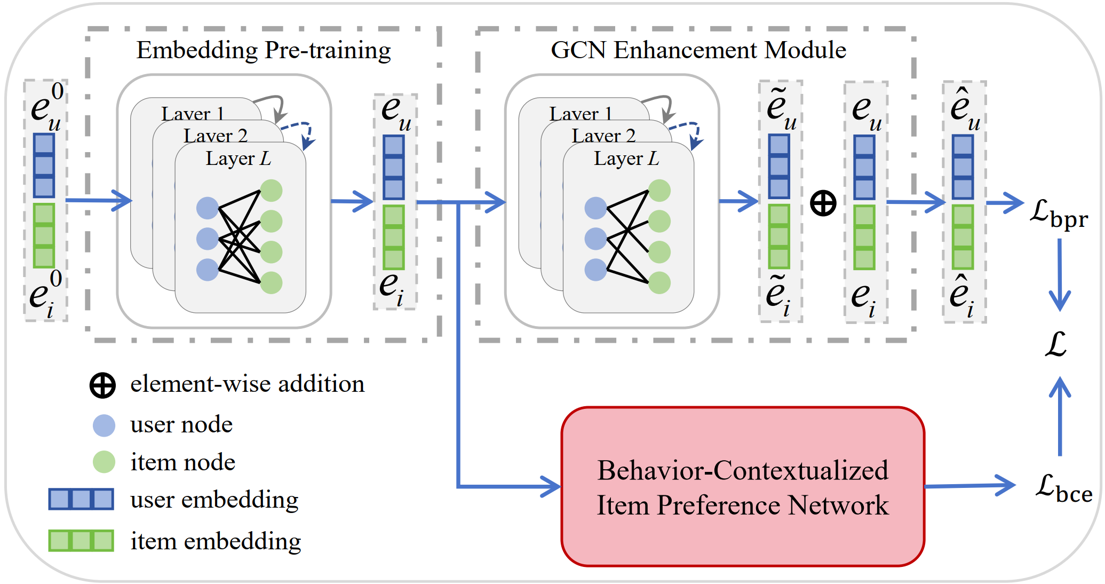
3 Behavior-Contextualized Item Preference Modeling for Multi-Behavior Recommendation
Mingshi Yan, Fan Liu, Zhiyong Cheng, Jing Sun, Fuming Sun, Zhiyong Cheng, Yahong Han
SIGIR 2024, (Project Page) (Preprint)
Multi-behavior recommendation methods address data sparsity in traditional single-behavior approaches by leveraging auxiliary behaviors to infer user preferences. However, directly transferring these preferences can introduce noise due to variations in user attention. To tackle this, we propose Behavior-Contextualized Item Preference Modeling (BCIPM), which learns specific item preferences within each behavior and only considers relevant preferences for the target behavior. Auxiliary behaviors are used for training, refining the learning process without affecting target behavior accuracy. Additionally, pre-training initial embeddings enriches item-aware preferences, especially when target behavior data is sparse. Experiments on four datasets show BCIPM outperforms state-of-the-art models, proving its effectiveness.